 您的位置:
您的位置:




紧接着Galbot又和团队成员在线下展位接待黄教主,现场展示无人零售的取货能力,大获赞誉。
一时之间,银河通用备受全球瞩目,这家初创型企业凭什么获黄教主如此垂青?

今天,银河通用以发布全球首个端到端具身抓取基础大模型(FoundationModel)给出一个圆满的回答。
银河通用联合北京智源人工智能研究院(BAAI)及北京大学和香港大学研究人员,郑重发布首个全面泛化的端到端具身抓取基础大模型GraspVLA。
GraspVLA的训练包含预训练和后训练两部分。
其中预训练完全基于合成大数据,训练数据达到了有史以来最大的数据体量——十亿帧「视觉-语言-动作」对,掌握泛化闭环抓取能力、达成基础模型;预训练后,模型可直接Sim2Real在未见过的、千变万化的真实场景和物体上零样本测试,全球首次全面展现了七大卓越的泛化能力,满足大多数产品的需求;而针对特别需求,后训练仅需小样本学习即可迁移基础能力到特定场景,维持高泛化性的同时形成符合产品需求的专业技能。
作为真正意义的端到端具身基础大模型,GraspVLA展示了无需大规模真实数据、仅通过合成数据达到基础模型的预训练过程,和进一步通过小样本微调使基础“通才”快速成长为指定场景“专家”的能力,定义了VLA发展的新范式。
这一范式具有重要意义,一举打破了世界范围内具身通用机器人当前发展的两大瓶颈。
数据瓶颈
真实数据采集不仅非常昂贵,且很难覆盖所有可能的实际应用场景,导致数据量不够无法训练出基础模型、采集成本过大以致无法盈利。即便不计成本地采集,由于人形机器人硬件远未收敛,随着硬件更新,原有的数据效力将大打折扣,造成大规模的浪费。
泛化瓶颈
数据的缺乏直接限制了机器人的泛化性和通用性。大部分机器人只能在特定的环境、特定的物体和特定的条件下完成专用任务,人形机器人无法实现规模商业化。
以GraspVLA为代表的银河通用技术路线具有低成本、大数据、高泛化的特点,突破了具身智能的发展瓶颈,无愧于托举起芯片巨头下一代核心产品的重担,将在2025年引领端到端具身大模型走向规模商业化!
下面让我们详细了解这一新范式经受的一系列泛化性测试以及展示出的基础模型的强大迁移能力。
VLA预训练如何才算达到基础模型?“金标准”来检验!
近年来,具身大模型虽在泛化性上取得一定进展,包括RDT初步展示了对不同背景和同一类别不同外观物体泛化的能力,OpenVLA、π0、GR-2等进一步展示了对干扰物、平面位置泛化的能力。
但时至今日,端到端具身大模型的泛化性仍然达不到真实需求,无法支撑产品落地。基于此,我们首次给出了VLA达到基础模型需满足的七大泛化金标准。以下内容均为未见过的场景和物体进行零样本测试的结果,展现了GraspVLA单一模型的七大全面泛化能力。
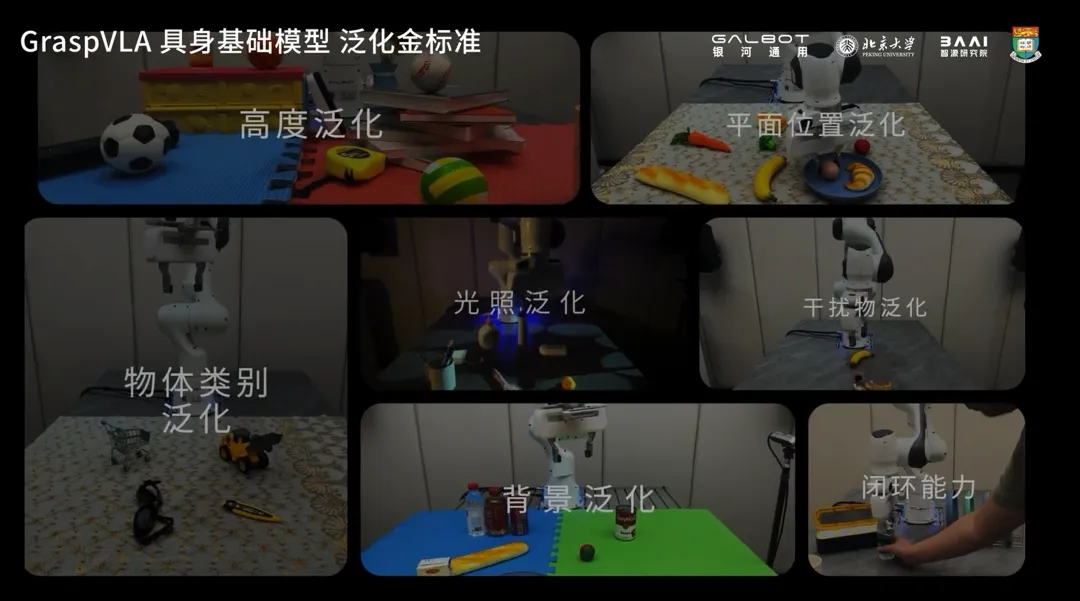
01
光照泛化:光影百变,能力不变
咖啡厅、便利店、生产车间、KTV等真实工作环境中的光照条件各异,光线的冷暖、强弱变化不尽相同,既有渐变也有骤变。面对以上各种情景,GraspVLA都不出意外,表现稳定:

视频为二倍速播放
甚至是在极端黑暗环境下移动目标物体,GraspVLA也能准确找到并正常抓取:

视频为二倍速播放
02
背景泛化:万千纹理,始终如一
实际环境中机器人工作场景不尽相同,面对不同材质、不同纹理的桌面和操作台,甚至动态变化的背景画面,GraspVLA皆不受影响,稳稳出手:

视频为三倍速播放
同样的,面对动态变化的背景画面,GraspVLA亦不受影响(需要注意的是,GraspVLA采用双相机视角作为输入,演示视频拍摄的视角对应了机器人正面的相机视角):

视频为三倍速播放
03
平面位置泛化:平移旋转,随机应变
将物体在桌面上随意平移、旋转,GraspVLA仍旧轻车熟路:

视频为二倍速播放
04
空间高度泛化:高低错落,从容不迫
GraspVLA具备强大的高度泛化能力,即便是面对物体摆放高低错落的工作台,用户也不用担心模型蒙圈:

视频为二倍速播放
05
动作策略泛化:闭环调整,随心应对
GraspVLA实时进行推理决策,不仅会移动跟随目标,对于物体竖放、倒放等不同摆放方式,还可根据物体和夹爪的位姿自动调整策略,选择最安全合理的抓取方式,处理复杂情况得心应手:

06
动态干扰泛化:超强抗扰,稳定抓取
真实工作场景复杂多变,机器人在执行任务时常常会受到干扰。在工作过程中,即使往工作空间中随意添加干扰物体,甚至发生撞击并使目标物体随机移位,GraspVLA依然能够稳定地完成任务:

视频为二倍速播放
07
物体类别泛化:开放词汇,触类旁通
上述测试中,所有物体、场景、摆放方式均未进行任何训练,GraspVLA仅通过仿真合成数据学习到的语义和动作能力,实现了在真实世界中零样本泛化测试。
此外,通过把仿真合成的动作数据和海量互联网语义数据巧妙地联合训练,对于没有学习过动作数据的物体类别,GraspVLA也能把已掌握的动作能力泛化迁移:

视频为三倍速播放
产品有特殊需求?一人天数据后训练迅速对齐!
经过合成大数据的预训练,GraspVLA已经天然满足大多数应用需求,但是在产品和特定场景中常常有一些特殊需求。这里我们以商超、工厂、家庭中的三个需要后训练的情形进行举例,展示GraspVLA对新需求的快速适应及迁移能力。
01
迅速服从指定规范并“举一反三”
以商超场景为例,虽然GraspVLA具有泛化的抓取能力,预训练后即可轻松抓取指定商品,但用户希望模型按照顺序取出同类商品。

视频为二倍速播放
02
迅速掌握新词汇,拓展新类别
工业场景中,往往有大量行业专用的特殊零件。虽然模型仅需预训练就可以抓起任意零件,但难以直接根据语言指令抓起对应物体,比如指定“抓取车窗控制器”,但模型抓起了接线座。

视频为二倍速播放
为了提升模型识别罕见零件的能力,仅需采集少量轨迹进行快速后训练。GraspVLA迅速掌握了诸如接线座(WiringBase)、三角板(TriangularPanel)、黑色软管(BlackHose)等特殊工业名词,能从任意摆放的密集场景中精准找出对应零件:

视频为三倍速播放
03
迅速对齐人类偏好
在家庭场景中,人们对机器人的行为会有特定的偏好,例如抓取杯子时不要碰到杯子内壁。同样通过采集少量带偏好的抓取轨迹,GraspVLA即可学会按照自然语义抓取:

对齐前,视频为三倍速播放

对齐后,视频为三倍速播放
由此可见,GraspVLA在预训练中已经充分掌握识别物品、抓取物品、多维度泛化的基础能力,使其在不同场景中针对特定需求规模化应用时,可以低成本高效拓展,这是VLA模型商业化应用中必备的能力。
VLA新范式的现在与将来
抓取是操作技能的基础,GraspVLA的发布树立了一个重要的里程碑,奠定了以仿真合成大数据预训练为核心的具身基础大模型的技术路线,开创了该领域发展的全新范式。
支撑这一范式的关键是合成大数据。
银河通用基于多年合成仿真数据的经验,坚持合成仿真数据的研究,开创性地研发出一套针对端到端VLA模型预训练的全仿真合成数据生产管线,在短短一周内就能生成全球规模最大的十亿级机器人操作数据集(包含视频-语言-动作三个模态)。
借助Isaac平台的加持,团队进一步提高了数据的物理真实性和物理渲染的并行度,确保了训练数据的高质量和低成本。即使硬件发生更新,该技术方案也能快速更新数据而不产生高附加成本,让企业没有数据沉没成本、减少硬件迭代的阻力。银河通用的预训练全合成大数据方案在人力和资金投入上成本更低,时间效率更高,可持续发展性更好。
此外,面对产品落地中的特别需求,GraspVLA的基座属性使得它仅需百条真实轨迹即可让预训练模型理解新任务并举一反三,实现了“一人一天完成产品部署”的通用机器人落地愿景,为VLA大规模商业化落地开辟了一条极具潜力的道路。
与此同时,联合研发团队在过去一年里还在导航VLA模型(NaVid系列模型)的研究上取得了重大突破,我们将陆续展示和介绍该系列导航VLA模型的泛化能力和涌现现象。
面向未来,我们将快速推出覆盖多技能的具身基础大模型,全面整合团队从抓到放、从关节类物体到柔性物体操作的各类任务的合成数据,持续依靠合成大数据作为唯一预训练来源,释放前所未有的潜力与能力,定义具身智能的ChatGPT时刻,推动人形机器人出现下一个高峰。
敬请期待我们的更多突破与成果。
